On Infrastructure as Code and Bit Rot

Table of Contents
The architecture of the infrastructure-as-code (IaC) tooling you use will determine the level to which your IaC definitions are exposed to bit rot.
This is a maxim I have arrived at after working with multiple IaC tool sets, both professionally and personally, over the last few years. In this blog post, I will explain how I arrived at this maxim by describing three architectural patterns for IaC tools, each with differing levels of risk for bit rot.
What is this bit rot business?⌗
Wikipedia defines bit rot as:
[...] a slow deterioration of software quality over time or its diminishing responsiveness that will eventually lead to software becoming faulty, unusable, or in need of an upgrade.
In the context of IaC, bit rot is the decay of deployability of an IaC definition.
In other words, with the passage of time, bit rot reduces the usability of an IaC definition, making it undeployable without modification.
I use the term IaC definition in this post to describe one or more files which contain
the definition for infrastructure resources. For example, IaC definitions can be written
in YAML, JSON, or a domain-specific language. The definition files are processed by a
piece of software in order to create/update/delete infrastructure resources.
Bit rot sets in when the format, version, or syntax of an IaC definition diverges from the format, version, or syntax supported by the latest version of software which deploys the IaC definition. The software moves forward with new versions, new features, refactors, etc, while the IaC definition remains static, becoming out of sync with the latest version of the tool. To deploy the IaC definition, it needs to be brought back into sync with the format/version/syntax that the latest version of the tool supports.
Bit rot is hard to detect, and usually only comes to light at the point where an IaC definition needs to be deployed, which is of course the worst possible moment to realize that the IaC definition may not be usable.
IaC tool architectures⌗
I've started characterizing IaC tools into one of three architectures, each of which have differing levels of exposure to bit rot. The three architectures are:
- User-side architecture
- Service-side architecture
- Hybrid architecture
I've so named them because they describe where the heavy lift of processing the IaC definition happens: on the user side of the user/service boundary, on the service side, or a mix of both.
The user-side architecture⌗
In the user-side architecture, there is a heavy dependency on user-side tooling to process IaC definitions. The tooling processes IaC definitions by parsing one or more files containing YAML, JSON, or a domain-specific language (DSL) and may also compile code, or execute instructions to build the definitions into one or more artifacts which can be used to deploy infrastructure resources.
In the figure below, I show a user-side architecture where, on the left, the IaC tool processes one or more definition files and then makes API calls to manage infrastructure resources.
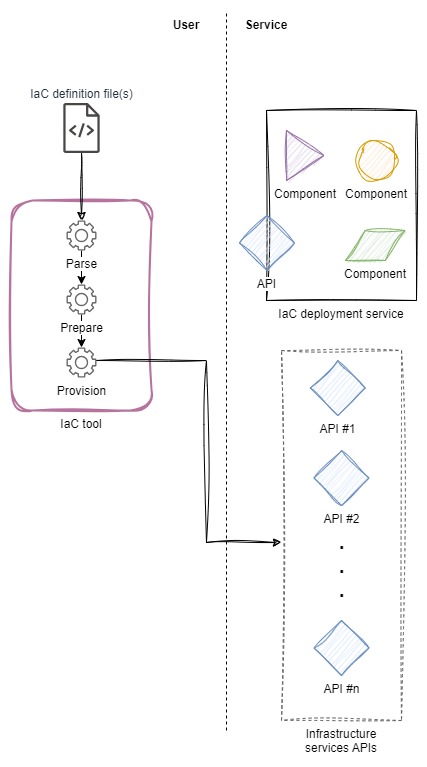
In this architecture, there is a tight coupling between the format, version, and content of the IaC definitions and the version of the tooling. However, development and releases of the definitions and the tooling are decoupled. Taken together, this creates opportunity for the definitions and the tooling to drift apart, up to the point where the definitions are no longer deployable by newer versions of the tooling.
This is where bit rot is realized.
To bring the definitions and tooling back into sync requires realigning the two, usually by moving the definitions closer to the tooling as opposed to downgrading the tooling. In so doing, changes are introduced to the blueprint for the infrastructure. Such changes are not without risk, and require careful thought, planning, and testing. Closing the gap between IaC definitions and the tooling is not without its challenges.
The upside to the user-side architecture is the increased control over processing the IaC definitions. This is especially true when the tooling involved is open source (in both the "source available" and license-permitted sense) as it allows for customization of the tooling to meet bespoke use cases and needs.
The service-side architecture⌗
In the service-side architecture, there is no domain-specific tooling required to make the IaC definitions usable. Once created using the editor/IDE of choice (we're all using Vim though, right? :wq) and structured in the right syntax, the definitions are immediately usable by the IaC deployment service.
The mechanism to feed the definitions to the service can be a web console, CLI tool, or other tooling. Note, however, that this mechanism doesn't process the definitions and only serves to move the definition from where the definition is created up into the service.
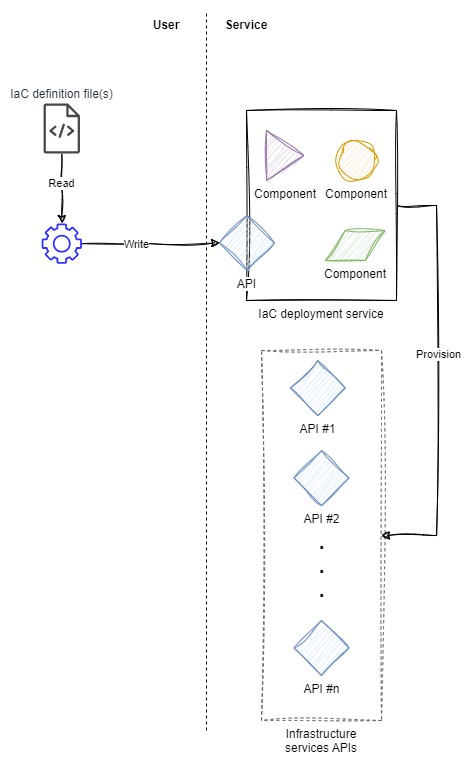
The service in this architecture takes on the burden of processing the definition, compiling code, or executing instructions--per the service's operation--and then applying the result to deploy infrastructure resources. Compared to the user-side architecture, many responsibilities have shifted to the service, with the remaining responsibilities for the user being to create a syntactically accurate and properly descriptive IaC definition.
The IaC deployment service may treat the syntax, format, and features of its IaC definition documents like an API. That is to say, it may treat them like a contract. The service may continue to honor and use definitions even if they were created well in the past, so long as the definition documents continue to adhere to the contract.
When using an IaC system that aligns to the service-side architecture and treats its input as a contract, the risk of bit rot is less than a system aligned to the user-side architecture.
The trade-off with such a system is it may be more conservative in the features and capabilities of its definitions than a system aligned to the user-side architecture. In a service-side architecture, there is one service for all users; changes to the service may be slower, more cautious to be released, and may lag behind user-side systems. In user-side systems, users can make their own choices when to upgrade, what version of the tool to run, and so on, and so the blast radius of a regression that occurs in a user-side system release is less than "all users" as the case would be in a service-side system.
The hybrid architecture⌗
Of course, there is a middle ground: a mix of the two architectures above. In the hybrid architecture, there is tooling that runs user-side to process a definition or some code, turning it into an artifact that can be fed to a service which does the heavy lift of creating the resources.
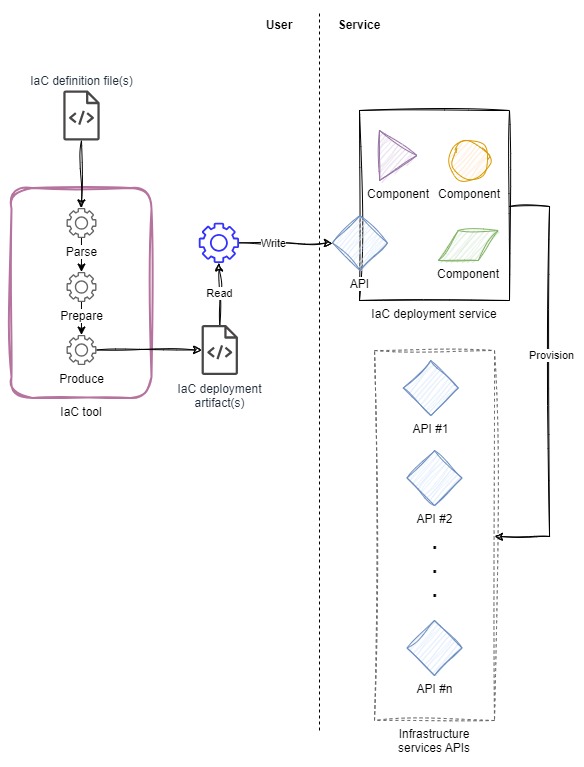
The hybrid architecture inherits the benefits and drawbacks of the user-side and service-side architectures.
Examples⌗
Below, I outline examples of each architecture. The tools and services I'm using as examples are (1) tools and services I have direct experience with, and (2) tools and services which are well known (at least within the AWS ecosystem).
User-side architecture example⌗
Terraform is an example of a user-side architecture tool.
Terraform processes one or more modules, which are collections of .tf files
written in
Terraform Configuration Language,
and builds a plan for creating resources based on the declarations in the
modules. When applying the plan, Terraform makes the necessary calls to service APIs to
create, update, or destroy resources.
An example where Terraform users experienced bit rot is during the
upgrade to Terraform v0.12.
Terraform v0.12 introduced a number of
breaking changes in the configuration language
which required special consideration when upgrading to v0.12. Any
modules which were used with prior versions of Terraform had to be evaluated
for compatibility with v0.12 and, where required, updated using Terraform
v0.12's 0.12upgrade sub-command, or manually by following HashiCorp's
upgrade instructions. In either case, modules had to be realigned to the
tool to accommodate an advancement which had taken place in the tool.
However, Terraform is actually more complicated than just the tool itself. The command line tool is more like a platform, providing the fundamentals of the system while third-parties (or HashiCorp themselves) write providers which contain the logic for talking to cloud providers, SaaS services, and other APIs. Providers add a set of resource types and/or data sources that Terraform can manage. The relationship between components ends up looking like this:
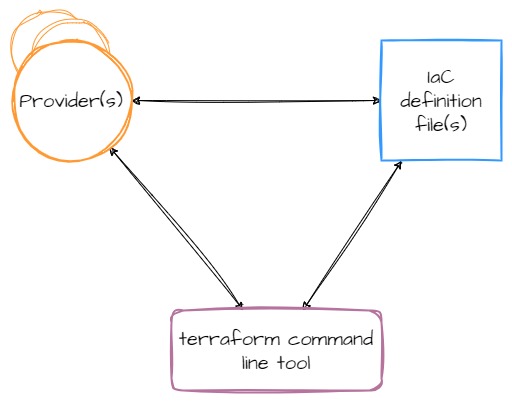
Additionally, since providers (like Terraform itself) are compiled code, your compute platform--operating system and architecture--are also part of this relationship.
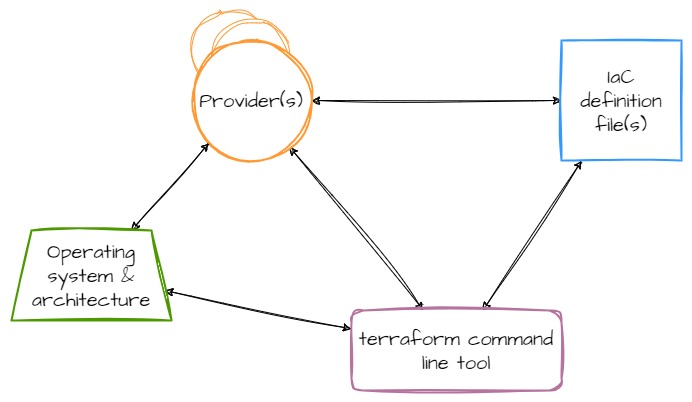
The arrows in these diagrams represent a coupling between components, and therefore, represent a place in the system where components can drift apart and where bit rot can seep in.
For example, at one point, the AWS provider was not being built for OpenBSD systems. This meant that as the AWS provider moved forward and gained new features (which usually means it supports new resources and features from AWS), OpenBSD users were stuck on the version of the provider which had been built for OpenBSD. And because there is a coupling between the provider(s) and the IaC definition files, the IaC definitions could not move forward either. They rotted. OpenBSD users were stuck managing whatever set of resources that version of the provider supported and nothing newer. This remained the case from somewhere in the 2.x version of the provider until 4.39.0.
Here's another example. Note the cyclic dependency between operating system,
the Terraform tool, and the providers in the diagram above. I recently
installed Terraform on an OpenBSD system to do some work on a project I hadn't
touched in a while. I ran a plan on the project, which failed, because one of
the utility providers the project uses was at a version too old for the
version of Terraform (bit rot). However, this provider was not being built on
OpenBSD any longer (seems to be a pattern). I was deadlocked. My operating
system is a fixed constraint, the version of Terraform installed is what my
operating system has bundled in their software catalog, I need the provider to
work because it's being used in my IaC code, but the provider doesn't support
my operating system... And around I go, stuck in this cyclic dependency loop.
Service-side architecture example⌗
AWS CloudFormation is an example of a service-side architecture.
CloudFormation processes templates--written in JSON or YAML--which define cloud resources, and executes the necessary API calls to create, update, or destroy those resources.
The basic workflow for working with CloudFormation is to use your editor of choice to create a template and then use either the AWS CLI or AWS Console to feed the template to CloudFormation. There is no processing, transforming, or compiling of anything on the user-side.
There are user-side tools which can be used with CloudFormation. The CloudFormation CLI helps you create custom resources and modules, CloudFormation rain is a tool for working with CloudFormation templates and stacks, and CloudFormation lint is a tool for checking the correctness of the templates you write. All of these tools aid in the use of CloudFormation, but are not required for that primary workflow of "create template, load template".
I cannot think of a single example where a template I've created has needed modification in order for CloudFormation to process it, even if the template was months or years old. CloudFormation is a good example of a service that commits to the "contract" of its input.
The format and features of CloudFormation templates have changed over time.
Those changes have been conservative, and in all the cases I can remember,
available only when the template explicitly calls for them through a
template transform.
An example of this is the
ForEach
function which is only available when applying the AWS::LanguageExtensions
transform. Unless explicitly requested, templates don't load any transforms
which means features which enhance the template language or format don't get
activated.
This "feature flag"-like mechanism of template transforms helps reinforce the contract that templates will continue to work as expected, even when newer features are added to the template construct.
Hybrid architecture example⌗
The AWS Cloud Development Kit (CDK) is an example of a hybrid architecture.
With AWS CDK, you use one of the supported programming languages, such as TypeScript, Python, Java, or Go to define your IaC resources. AWS CDK then synthesizes one or more CloudFormation templates from this definition and calls on CloudFormation to process the templates.
Relatively early in its lifetime, AWS CDK crossed a major version boundary, going from v1.x to v2.x. Moving your usage of AWS CDK to v2 meant making multiple changes to any project that had been developed using v1; the v2 tooling wasn't compatible with projects built with v1. Projects built for v1 started to experience bit rot as soon as v2 was released.
However, the deployable artifacts--the synthesized CloudFormation templates--remained usable for all the same reasons mentioned in the Service-side architectures example section above.
Summary⌗
In this post, I've attempted to explain how I arrived at the following maxim:
The architecture of the infrastructure-as-code (IaC) tooling you use will determine the level to which your IaC definitions are exposed to bit rot.
My experience using multiple IaC tools over the last several years has shown me that the risk level of an IaC definition being unusable is tightly related to the architecture of the tool I'm using. By classifying an IaC tool into one of the three architectural patterns I describe in this post, you can anticipate the risk of bit rot for your IaC definitions.
When deciding on an IaC tool, consider including a review of the tool's architecture and the associated risk to bit rot in the decision criteria. This will help you examine the tool with a long range perspective, not just on the near-term need.
Disclaimer: The opinions and information expressed in this blog article are my own and not necessarily those of Amazon Web Services or Amazon, Inc.